
Artículo publicado:
Artículo actualizado:
We propose adding a
Jeremy Howard/llms.txtfile to websites that are designed for reading by language models, not just humans.llms.txtis a file that outlines the information that a model may want to retrieve (with links) when assembling context for LLM prompts relevant to a website.
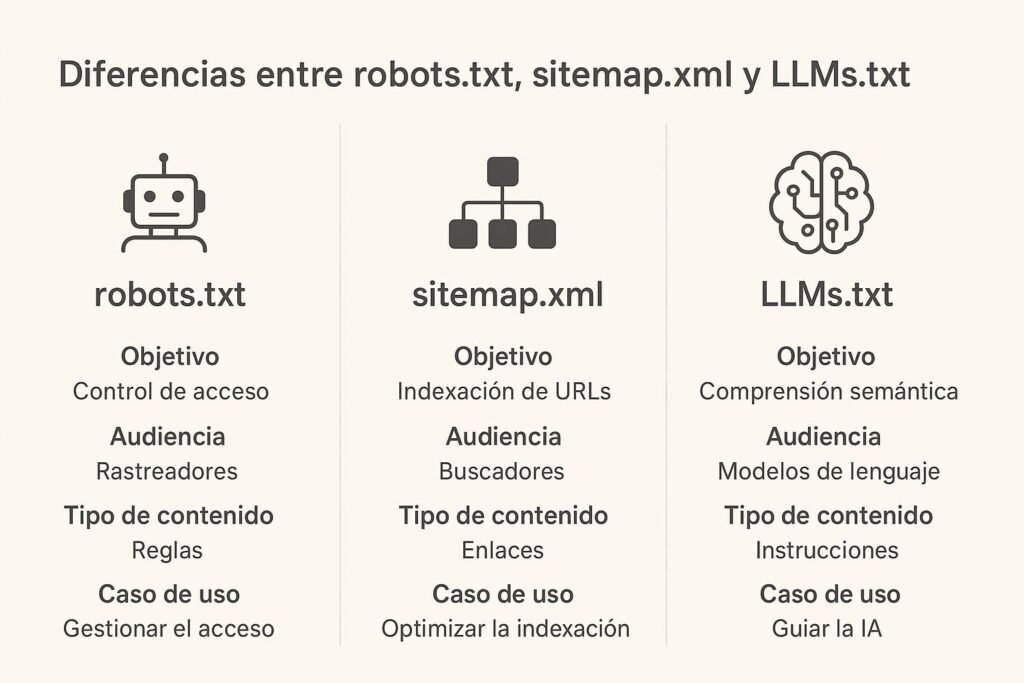
Proponemos añadir un archivo /llms.txt a los sitios web diseñados para la lectura por modelos de lenguaje, no solo por humanos. llms.txt es un archivo que describe la información que un modelo podría querer recuperar (con enlaces) al compilar el contexto para las indicaciones de LLM relevantes para un sitio web. / Jeremy Howard| Característica | Robots.txt | Sitemap.xml | LLMs.txt |
|---|---|---|---|
| Propósito | Controla el acceso a rastreadores | Lista URLs para indexar | Estructura semántica optimizada para IA |
| Audiencia | Rastreadores web | Motores de búsqueda | Modelos de IA y motores generativos |
| Formato | Texto plano | XML | Markdown |
| Función | Control de indexación | Navegación estructurada | Interpretación y priorización semántica |
| Caso de uso | Gestión y control SEO | Indexación de contenido en buscadores | Visibilidad en ecosistemas IA |



# [NOMBRE_DE_SU_SITIO.COM]
> Resumen conciso de qué trata el sitio web. Esta sección utiliza un bloque de cita para proporcionar contexto global a los Modelos de Lenguaje Grande (LLMs).
## Estructura de Servicios
- [Servicio A: Título de la página](https://suweb.com/servicio-a/): Descripción detallada del servicio y su propuesta de valor.
- [Servicio B: Título de la página](https://suweb.com/servicio-b/): Descripción de cómo se ejecuta el servicio o qué incluye.
- [Página de Contacto](https://suweb.com/contacto/): Información sobre cómo iniciar un proyecto.
## Casos de Estudio
- [Caso 1: Nombre del Cliente](https://suweb.com/caso-1/): Breve resumen del desafío, la solución y el resultado clave del proyecto.
- [Caso 2: Ejemplo de Éxito](https://suweb.com/caso-2/): Éxito enfocado en la métrica más importante (ventas, tráfico, etc.).
## Artículos Destacados
- [Artículo A: Título del blog](https://suweb.com/blog/articulo-a/): El artículo cubre a fondo el tema X y ofrece una guía práctica.
- [Artículo B: Título del blog](https://suweb.com/blog/articulo-b/): Contenido centrado en la herramienta o estrategia Z.
## Documentación Legal y Corporativa
- [Acerca de Nosotros](https://suweb.com/about/): Información institucional sobre la misión y la historia de la empresa.
- [Política de Privacidad](https://suweb.com/privacidad/): Documento que detalla el manejo y la protección de datos del usuario.
- [Aviso Legal](https://suweb.com/legal/): Términos legales y condiciones de uso del sitio.
# Answer.AI company website
> Answer.AI is a new kind of AI R&D lab which creates practical end-user products based on foundational research breakthroughs. Answer.AI is a public benefit corporation.
## Docs
- [Launch post describing Answer.AI's mission and purpose](https://www.answer.ai/posts/2023-12-12-launch.md)
- [Describes Answer.AI, a "new old kind of R&D lab" - Lessons from history’s greatest R&D labs](https://www.answer.ai/posts/2024-01-26-freaktakes-lessons.md)
- [Answer.AI projects](https://www.answer.ai/overview.md): Brief descriptions and dates of released Answer.AI projects
# Hostinger
> Comprehensive overview of Hostinger's web hosting services, tools, website builders, domain options, and specialized hosting solutions.
## Core Hosting Services
- [Web Hosting](https://www.hostinger.com/web-hosting): Affordable and reliable web hosting solutions.
- [WordPress Hosting](https://www.hostinger.com/wordpress-hosting): Optimized hosting for WordPress websites.
- [Cloud Hosting](https://www.hostinger.com/cloud-hosting): Scalable cloud infrastructure for growing websites.
- [VPS Hosting](https://www.hostinger.com/vps-hosting): Virtual private server solutions with dedicated resources.
- [Cheap Web Hosting](https://www.hostinger.com/cheap-web-hosting): Budget-friendly hosting options without compromising quality.
## Domain Services
- [Domain Name Search](https://www.hostinger.com/domain-name-search): Find and register your perfect domain name.
- [Free Domain](https://www.hostinger.com/free-domain): Get a free domain with selected hosting packages.
- [Cheap Domain Names](https://www.hostinger.com/cheap-domain-names): Affordable domain registration options.
- [Domain Transfer](https://www.hostinger.com/transfer-domain): Transfer your existing domain to Hostinger.
- [WHOIS Lookup](https://www.hostinger.com/whois): Check domain ownership and registration information.
## Website Building Tools
- [Website Builder](https://www.hostinger.com/website-builder): Easy drag-and-drop website creation tool.
- [AI Website Builder](https://www.hostinger.com/ai-website-builder): Create websites quickly with AI assistance.
- [AI Website Builder for WordPress](https://www.hostinger.com/ai-website-builder-for-wordpress): AI-powered WordPress site creation.
- [Landing Page Builder](https://www.hostinger.com/landing-page-builder): Create effective landing pages.
- [Logo Maker](https://www.hostinger.com/logo-maker): Design professional logos for your brand.
- [Blog Maker](https://www.hostinger.com/blog-maker): Easy blog creation platform.
I'm not aware of anything in that regard. In my POV, LLMs have trained on – read & parsed – normal web pages since the beginning, it seems a given that they have no problems dealing with HTML. Why would they want to see a page that no user sees? And, if they check for equivalence, why not use HTML?
— John Mueller (@johnmu.com) 23 de noviembre de 2025, 22:29
No tengo conocimiento de nada al respecto. Desde mi punto de vista, los LLM se han entrenado con páginas web normales (leyendo y analizando) desde el principio; parece obvio que no tienen problemas con HTML. ¿Por qué querrían ver una página que ningún usuario ve? Y, si comprueban la equivalencia, ¿por qué no usar HTML? / John Mueller